Server Outage or Silent Collapse? Why Your Favorite AI App is a Thin Layer Over a Cloud Megacorp's API
- rescuerevenuellc
- Nov 18, 2025
- 12 min read

You're mid-conversation with ChatGPT, crafting the perfect email response, when suddenly—poof. The screen freezes. The little thinking dots vanish. Your AI assistant has ghosted you harder than your college roommate who still owes you $200.
Welcome to November 18, 2025, where a Cloudflare hiccup reminded us all that your "cutting-edge AI companion" is basically a very expensive walkie-talkie that stops working when someone trips over the wrong cable.

Here's the uncomfortable truth nobody in Silicon Valley wants to admit over their oat milk lattes: that sleek AI app you've been bragging about? It's not actually intelligent. It's not even really "yours." It's a thin wrapper around someone else's API, running on someone else's servers, protected by someone else's infrastructure. And when that infrastructure decides to take an unscheduled nap, your revolutionary AI solution turns into a very expensive paperweight.
This Morning's Wake-Up Call: When Cloudflare Sneezes, AI Catches a Cold
This morning's Cloudflare outage wasn't just an inconvenience—it was a masterclass in cascading failure. Within minutes, ChatGPT went dark. X (formerly Twitter, because we're still not over that rebrand) became unusable. Even some multiplayer games crashed, because apparently, everything is connected to everything now, and we've built our digital infrastructure like a house of cards in a wind tunnel.
The Domino Effect Nobody Talks About

According to reports from Windows Central, the outage didn't just affect one or two services—it created a ripple effect across the entire internet ecosystem (Wilson). When Cloudflare's infrastructure experienced what they diplomatically called "sporadic disruptions," it exposed just how interconnected and fragile our AI service dependencies really are. CNBC reported that the issue stemmed from a massive traffic spike that overwhelmed Cloudflare's systems, proving that even the companies designed to handle internet-scale traffic can buckle under pressure (Shiflett and Menn).
But here's the kicker: this isn't new. This isn't surprising. This is just Tuesday in the world of cloud infrastructure. The only surprise is that we keep acting surprised when it happens. It's like being shocked that it rains in Seattle—at some point, you need to buy an umbrella instead of shaking your fist at the sky.
For developers and product managers building AI applications, today's outage should be a flashing neon sign that reads: "Your backup plan better have a backup plan." Because when your primary AI provider goes down, your users don't care about Cloudflare's incident report—they just know your app doesn't work, and they're already downloading your competitor's solution.
Your "Revolutionary" AI App Is Just Someone Else's Computer (With Extra Steps)
Let's get real for a second. That AI chatbot you built? The one with the slick interface and the venture capital backing? Under the hood, it's making API calls to OpenAI, Anthropic, or Google. Your "proprietary AI solution" is essentially a really well-designed form that sends requests to someone else's server and formats the response with your brand colors. It's like claiming you're a chef because you can order takeout really efficiently.
The Infrastructure Jenga Tower
Modern AI applications are built on a stack that would make a Jenga tower look structurally sound. You've got your application layer (your actual code), sitting on top of the API layer (OpenAI, Anthropic, etc.), which sits on cloud infrastructure (AWS, Azure, Google Cloud), which is protected by services like Cloudflare, all of which depend on physical data centers, undersea cables, and hopefully someone remembered to pay the electric bill.
Every single layer is a potential point of failure. And here's the fun part: you usually only control one of those layers. The rest? You're just hoping everyone else did their job correctly. It's like being a passenger on a plane—you can control your seatbelt, but you're trusting a lot of other people with the flying part.

Why This Keeps Happening (Spoiler: It's Not Going Away)
The uncomfortable reality is that these outages aren't bugs in the system—they're features of the system. When you centralize infrastructure and create dependencies across millions of applications, you're essentially building a single point of failure with extra steps. The October 2025 AWS outage that disrupted services across the internet? That wasn't a failure of technology—it was the inevitable result of putting too many eggs in one very large, very complex basket (Ahmed).
According to ThousandEyes' analysis of the October AWS outage, the root cause was traced to a configuration change that cascaded through multiple availability zones, proving that even with redundancy built into the system, a single mistake can still bring everything down (Rosenfeld). Microsoft Azure experienced similar issues just days later, with an October 29 outage affecting services worldwide due to what was essentially a software bug in their load balancing infrastructure (Kovvuru).
But Wait—Doesn't Everything Break Sometimes?
Now, before the comments section erupts with "well actually" energy, let's address the elephant in the server room: yes, everything breaks sometimes. Your argument that "all technology fails eventually" is technically correct, which is the best kind of correct. But that's exactly the point—if we know everything fails, why are we still building systems that collapse like a house of cards when one thing goes wrong?
The Great Equalizer: When Tech Giants Stumble
The outage excuse has become so common it's practically a meme at this point. Google goes down? "Unprecedented traffic surge." Microsoft crashes? "Routine maintenance went sideways." Verizon drops calls? "Network optimization in progress." It's like we've collectively agreed to accept that billion-dollar companies with some of the smartest engineers on the planet just can't figure out how to keep servers running consistently.
And here's where it gets interesting: people who don't want to use AI love these outages. They're validation. "See? I told you this AI stuff was unreliable. I'll stick with my spreadsheets, thank you very much." And honestly? They're not entirely wrong. When your AI solution is less reliable than Excel running on a Windows 95 machine, you've got a problem.
AWS, Azure, and the Outage Hall of Fame
Let's take a quick trip down memory lane—or in this case, down the 2025 outage timeline. In October alone, we saw major disruptions from AWS and Azure within days of each other. CNN Business reported that a "tiny bug" in AWS's infrastructure spiraled into a massive outage that affected services across multiple regions, disrupting everything from streaming services to e-commerce platforms (Ahmed). The technical postmortem revealed that the issue stemmed from an automated system that was supposed to prevent failures but instead amplified them—irony so thick you could cut it with a knife.
Microsoft Azure's October 29 outage followed a similar pattern, with load balancing issues causing widespread service degradation across their global infrastructure (Kovvuru). The common thread in all these incidents? They weren't caused by hackers, natural disasters, or incompetence. They were caused by the inherent complexity of managing infrastructure at scale. When you're serving billions of requests per second, even a 0.01% error rate translates to millions of failures.

The lesson here isn't that cloud providers are bad at their jobs—it's that the job is incredibly hard, and perfect uptime is a myth we keep selling ourselves. If Amazon, Microsoft, and Google can't maintain 100% uptime with their essentially unlimited resources, what makes you think your AI app running on their infrastructure will be any different?
The Real Problem: You're Building on Quicksand and Calling It Innovation
Here's where we need to have an uncomfortable conversation about what we're actually building. Most AI applications today are essentially elaborate middleware—they take user input, format it nicely, send it to a third-party API, and display the response with some CSS flourishes. There's nothing inherently wrong with this approach, but let's not pretend we're building the next-generation of technology when we're essentially creating a fancy frontend for someone else's product.
Single Point of Failure Syndrome
The technical term for what most AI apps have is "single point of failure syndrome," though I prefer the more colloquial "putting all your eggs in one basket and then dropping the basket off a cliff." When your entire application depends on a single API endpoint, you're not building a product—you're building a very expensive dependency.
According to Portkey's analysis of enterprise AI infrastructure, organizations that rely on a single LLM provider face significant operational risks, with outages leading to complete service disruption and no fallback options ("Why Multi-LLM Provider Support").
The research shows that multi-model approaches aren't just nice-to-have features—they're essential for any production-grade AI application. Yet most startups and even established companies continue to build their entire infrastructure around a single provider, presumably because planning for failure is less sexy than pretending it won't happen.
The "It Won't Happen to Us" Delusion
Every developer has heard the whispered legend of the mythical "five nines" uptime—99.999% availability, which translates to about 5 minutes of downtime per year. It's spoken of in hushed tones, like Bigfoot or a bug-free codebase. The problem is that even if your cloud provider achieves five nines (they don't, but let's pretend), you're stacking multiple five-nines services on top of each other. Basic probability tells us that your actual uptime is the product of all those individual uptimes, and math is not your friend here.

Let's say your app depends on OpenAI's API (99.9% uptime), running on AWS (99.95% uptime), protected by Cloudflare (99.99% uptime). Your actual uptime? About 99.84%. That's about 14 hours of downtime per year, or more than an hour per month. And that's assuming everything goes perfectly and nothing else breaks. Spoiler alert: something else always breaks.
The real delusion isn't thinking your service won't go down—it's thinking that when it does, your users will understand and patiently wait for things to come back online. They won't. They'll tweet angrily, leave one-star reviews, and switch to a competitor. Because in 2025, nobody has patience for downtime anymore, even though we've somehow normalized it as just part of the technology experience.
The Practical Solution: Multi-Model Fallback Strategies That Actually Work
Alright, enough doom and gloom. Let's talk solutions—actual, practical solutions that don't require you to build your own data center or sacrifice your firstborn to the infrastructure gods. The answer isn't to avoid cloud services or abandon AI applications. The answer is to stop putting all your infrastructure eggs in one basket and start building systems that can actually handle failure gracefully.
What a Fallback Strategy Actually Looks Like
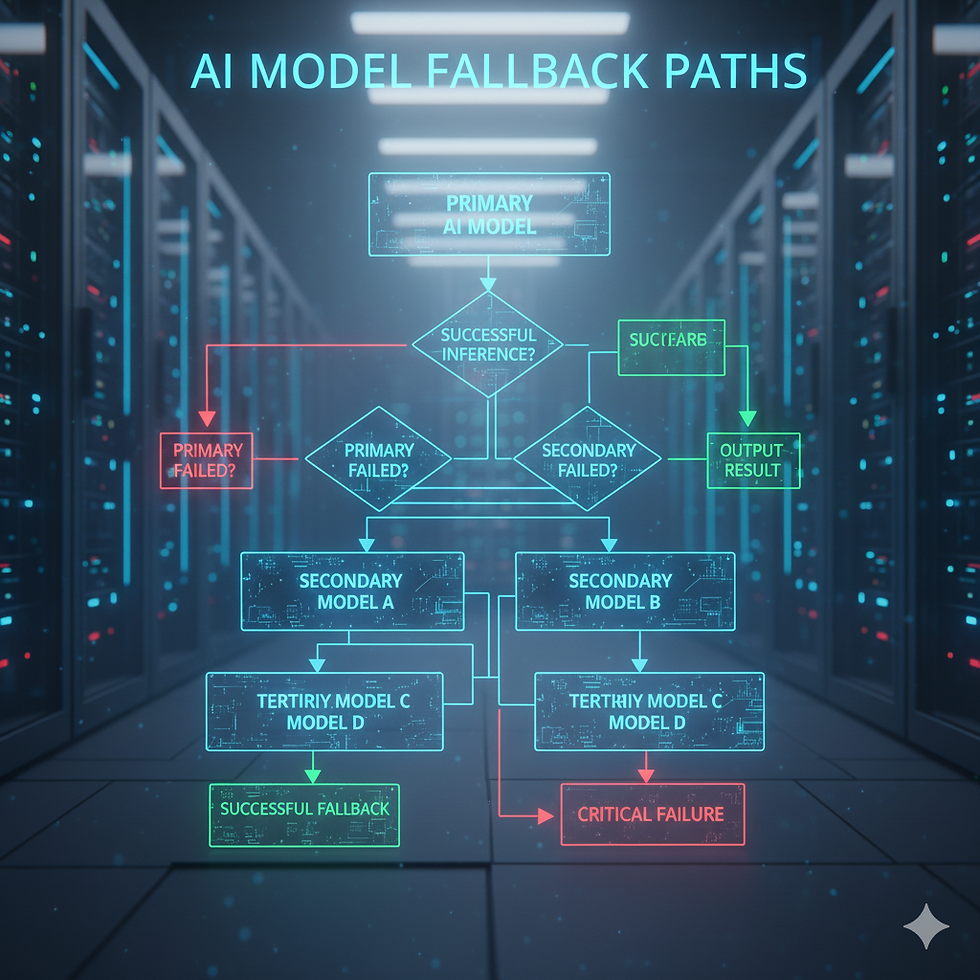
A multi-model fallback strategy is exactly what it sounds like: when your primary AI model goes down, you have a backup ready to go. Think of it like having a spare tire in your car—you hope you never need it, but when you do, you'll be really glad it's there instead of being stranded on the side of the information superhighway.
The key is to implement this in layers, with each layer providing progressively more basic functionality. Your primary layer might be GPT-4 or Claude, giving users the full premium experience. Your secondary layer could be a smaller, faster model like GPT-3.5 or an open-source alternative, providing core functionality with slightly reduced quality. Your tertiary layer—your absolute last resort—could be a locally-hosted model or even rule-based responses for critical functions.
According to enterprise AI infrastructure experts, the most effective implementations use a router-based approach that automatically detects failures and switches between providers without user intervention ("Why Multi-LLM Provider Support"). This means users get a slightly degraded experience instead of no experience at all—which is infinitely better from both a user satisfaction and business continuity perspective.
Open-Source LLMs as Your Insurance Policy
Here's where open-source models become your secret weapon. Models like fine-tuned versions of BERT, LLaMA, or Mistral can run locally or on your own infrastructure, providing a safety net that doesn't depend on external APIs. Yes, they might not be as capable as GPT-4. Yes, they require more setup and maintenance. But you know what they also don't do? Stop working when Cloudflare has a bad day.
The beauty of open-source LLMs is that they give you control. You can fine-tune them for your specific use case, run them on your own servers, and most importantly, guarantee they'll be available when everything else goes dark. They're like the reliable Honda Civic of AI models—not as flashy as the luxury options, but they'll get you where you need to go even when the fancy cars are in the shop.
For mission-critical features—things like customer support responses, basic query handling, or essential workflow automation—having a local fallback isn't just good practice, it's essential. Your users don't need the absolute best AI response 100% of the time. But they do need some response 100% of the time. That's the difference between a product people trust and a product people abandon.
Implementation Without the Headache
I know what you're thinking: "This sounds expensive and complicated." And you're not wrong—but it's less expensive than losing all your users when your primary provider goes down. The good news is that implementing a fallback strategy doesn't have to be a months-long engineering nightmare.
Start with abstraction layers. Instead of calling OpenAI's API directly throughout your codebase, create an abstraction layer that handles provider selection and failover. This way, when you need to switch providers or add fallbacks, you're changing one module instead of hunting through hundreds of files. It's basic software engineering, but you'd be surprised how many AI startups skip this step in their rush to market.
Next, implement health checks and circuit breakers. Monitor your API endpoints and automatically route traffic away from failing services before users even notice. This isn't cutting-edge technology—it's been standard practice in web development for years. The fact that so many AI applications don't do this is honestly baffling.
Finally, test your fallbacks regularly. It's not enough to have a backup system if you've never actually verified it works. Schedule regular failover tests, simulate outages, and make sure your team knows how to handle provider switches. Because the worst time to discover your fallback doesn't work is during an actual outage when users are already angry.
Your Action Plan: Building AI That Doesn't Faceplant When Cloudflare Hiccups
Alright, let's get practical. You've read this far, which means either you're procrastinating on actual work, or you're genuinely interested in building more resilient AI applications. Assuming it's the latter (no judgment if it's the former), here's your concrete action plan:
1. Audit Your Dependencies Today: Map out every external service your AI application depends on. Create a visual diagram showing your infrastructure stack from user interface down to physical servers. Identify every single point of failure. This will probably be depressing, but it's necessary.
2. Implement Abstraction Layers This Week: Stop calling API providers directly. Create an abstraction layer that sits between your application logic and external services. This single change makes everything else on this list easier and should have been done from day one, but better late than never.
3. Choose Your Fallback Models This Month: Research and select backup LLM providers. For most applications, this means picking a smaller, faster model from a different provider than your primary choice. Consider open-source options like fine-tuned BERT models or locally-hosted alternatives for critical functions.
4. Build Graceful Degradation Next Quarter: Design your application so that when AI features fail, core functionality remains available. Users should get a degraded experience, not a complete failure. Think of it like your car's limp mode—you won't win any races, but you can still get home.
5. Implement Health Checks and Monitoring Immediately: Set up monitoring for all external dependencies with automatic alerting. Configure circuit breakers that detect failures and route traffic to fallback systems before users notice problems. This isn't optional anymore.
6. Test Your Failover Quarterly: Schedule regular disaster recovery drills. Deliberately break your primary systems and verify your fallbacks work as expected. Document the process, measure recovery times, and fix any issues discovered during testing.
7. Document Everything and Train Your Team: Create runbooks for handling outages. Make sure everyone on your team knows how to manually trigger failovers and how to communicate with users during incidents. The middle of an outage is not the time to figure out who does what.
The reality is that building resilient AI applications isn't rocket science—it's just good engineering practices applied to a new technology. The principles of redundancy, failover, and graceful degradation have been around for decades. The only thing that's changed is that we're applying them to LLMs instead of databases or web servers.
If you're a developer or product manager reading this and thinking "this sounds like a lot of work," you're absolutely right. It is a lot of work. But you know what's more work? Explaining to your CEO why your application has been down for three hours because Cloudflare sneezed. Or watching your user base evaporate because they can't rely on your service. Or trying to raise your next funding round while explaining that yes, your application completely depends on a third-party API that goes down regularly.
The good news is that implementing these strategies doesn't have to happen overnight.
Start with the abstraction layer > Add monitoring > Implement a simple fallback
Each step makes your application more resilient, and each step is infinitely better than doing nothing and hoping the infrastructure gods smile upon you.
And if you're feeling overwhelmed by where to start or how to implement these strategies effectively in your specific context, that's exactly what experts in AI implementation are here for.

Whether you're a developer trying to architect more resilient systems or a product manager figuring out how to balance reliability with innovation, sometimes having someone who's navigated these challenges before can save you months of trial and error.
If you'd like to explore how to leverage AI more effectively for your role while building systems that actually stay online, feel free to reach out—because the best time to fix your infrastructure is before it breaks, not after.
Works Cited
Ahmed, Rishi. "How a tiny bug spiraled into a massive outage that took down the internet." *CNN Business*, 25 Oct. 2025, www.cnn.com/2025/10/25/tech/aws-outage-cause.
Kovvuru, Ismail. "Microsoft Azure Outage (Oct 29 2025): Root Cause, Impact and Technical Analysis." *Medium*, Oct. 2025, medium.com/@ismailkovvuru/microsoft-azure-outage-oct-29-2025-root-cause-impact-and-technical-analysis-3c7646d31703.
Rosenfeld, Meir. "AWS Outage Analysis: October 20, 2025." *ThousandEyes*, Oct. 2025, www.thousandeyes.com/blog/aws-outage-analysis-october-20-2025.
Shiflett, Shane and Joseph Menn. "Cloudflare says outage that hit X, ChatGPT and other sites is resolved." *CNBC*, 18 Nov. 2025, www.cnbc.com/2025/11/18/cloudflare-down-outage-traffic-spike-x-chatgpt.html.
"Why Multi-LLM Provider Support is Critical for Enterprises." *Portkey*, 8 Apr. 2025, portkey.ai/blog/multi-llm-support-for-enterprises/.
Wilson, Ben. "Cloudflare is down this morning, causing outages at X, OpenAI, and even some online games as sporadic disruptions continue." *Windows Central*, 18 Nov. 2025, www.windowscentral.com/software-apps/cloudflare-is-down-causing-outages-at-x-openai-and-even-taking-some-multiplayer-games-offline.


Comments