Stop Treating LLMs Like Google: Why Prompts Aren’t Just Search Queries
- rescuerevenuellc
- Oct 7, 2025
- 5 min read

If you talk to an LLM like it’s Google, don’t be shocked when it answers like the world’s most confident intern: fast, friendly, and occasionally making stuff up with a straight face.
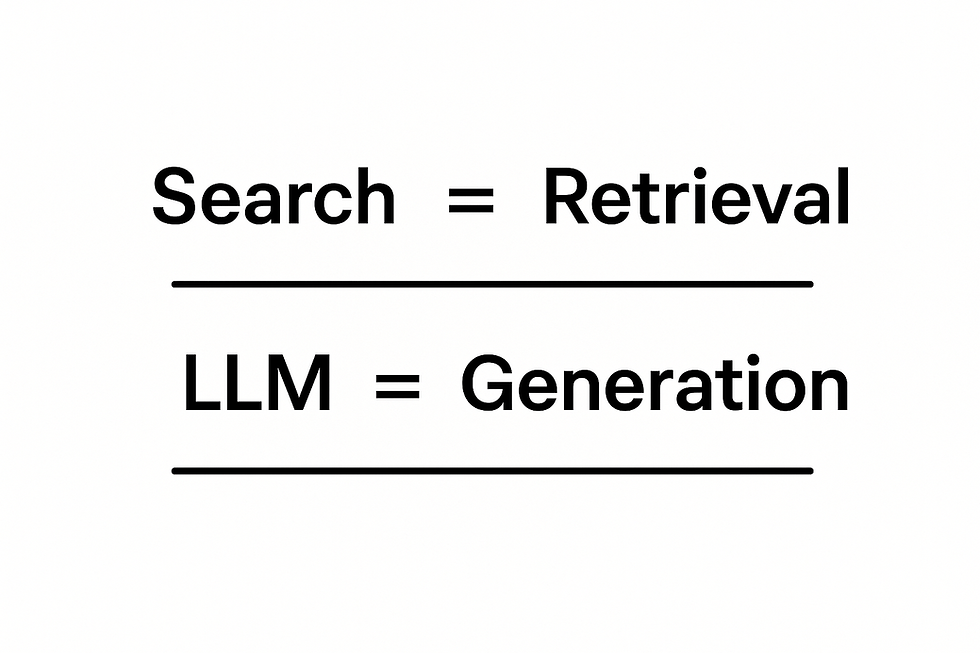
Search engines retrieve. LLMs generate.
That one difference is why your “quick question” often turns into 20 minutes of cleanup — and why “write better prompts” actually means “give better context and direction.” Wharton’s Prompting Science report shows tiny wording changes can dramatically swing results. Translation: your prompt is not a wish; it’s the brief. Wharton Generative AI Labs+1
The Google Reflex — Why We’re All Wired Wrong for LLMs
We grew up on keyword hunting: type a few magic words, skim links, click, repeat. That habit lingers when we open ChatGPT. But LLMs don’t go fetch; they compose—using patterns learned during training and whatever context you provide now. If your prompt lacks direction, the model fills the gaps with its best guess. That’s where the time sink starts. Wharton Generative AI Labs
From Keywords to Conversations: How Our Search Habits Mislead Us
“best marketing tools 2025” is a search query; “Act as a B2B SaaS growth strategist. Compare the top 5 AI-assisted marketing tools for <$10M ARR companies; output a table with pricing, integrations, and risks.” is a brief. The first asks the model to guess intent; the second defines it. Wharton’s testing underscores that even subtle prompt and evaluation tweaks swing outcomes, which is why clarity beats cleverness. Wharton Generative AI Labs
The Hidden Cost of “Just Ask It”: When Bad Prompts Waste Hours
Vague prompts look faster, but they backload the work onto you. You edit tone, fix structure, and redo sections the model was never told to produce. Empirically, prompt design is contingent: small changes → different behavior, quality, and usefulness. Treat your first prompt like a spec, not a shrug. arXiv
What LLMs Actually Do — They Generate, Not Retrieve
Think of Google as a librarian pointing to shelves. Think of an LLM as a very capable junior colleague who drafts based on patterns, your inputs, and constraints. That colleague does better work when you hand them a brief, not a riddle.
Context Is King: Why Background Info Changes Everything
“Give me a marketing plan” invites boilerplate. “Audience: B2B founders; Goal: increase demo-to-close by 15%; Constraints: no paid ads; Stack: HubSpot; Timeline: Q4” pulls the output toward your reality. Even the content world is adjusting: HBR notes that brand visibility is shifting from old-school SEO to being legible to LLMs — context-rich, structured, and aligned with user intent. Your inputs shape what the model can reliably generate. Harvard Business Review
Role, Format, and Framing — The Three Levers of Prompt Power
Give the model a role (“You are a pricing analyst”), a format (bullets, table, brief), and framing (what to optimize for). These levers are simple but powerful. They turn “answer me” into “work with me,” reducing variance that research repeatedly observes. Wharton Generative AI Labs
Prompting Like a Pro — Designing for Intent, Not Keywords
Good prompts aren’t poetic; they’re operational. Treat them like mini statements of work.
How to Structure Prompts That Guide LLMs to Useful Output
Setup (Context): Who’s the audience? What’s the goal? What constraints?
Instruction (Task): Exactly what you want produced.
Format (Output): Bullets, table, steps, JSON, outline.
Constraints (Bounds): Word count, tone, exclusions.
Exemplars (Optional): A sample to pattern-match.
Under the hood, this isn’t woo-woo; the 2025 surveys frame prompt design/optimization as a real search/optimization problem over discrete/continuous prompt spaces. In plain English: you can systematically iterate prompts toward better outcomes, not just vibe your way through. arXiv+1
Common Prompt Fails and What They Teach Us About Human Assumptions
No role: You get generic tone because you never hired the model for a job.
No format: You get a wall of text because you never asked for a table or checklist.
No constraints: You get meandering answers because you never set bounds.
Ambiguous objective: You get okay-ish output… for the wrong goal.
Bottom line from the research: ambiguity multiplies variance. Tighten the prompt; reduce surprise. Wharton Generative AI Labs
Real-World Example — Turning Search Queries into AI Collaborations
Let’s refactor a classic “searchy” ask into a collaborative brief.
Reframing a Question to Get a Strategic Plan Instead of a Summary
Search-style: “content strategy 2025.”
LLM-collab:“You are a senior content strategist. Build a 6-month plan for a SaaS with <$10M ARR. Include 2 themes/month, KPI targets (traffic → trials → paid), risks, and weekly sprint tasks. Output: table + 300-word narrative.”
That one prompt tees up role, format, constraints, and success metrics. No mind-reading required.
How Context Turns a One-Sentence Prompt into a Five-Minute Breakthrough
A consultant asks, “How do I grow newsletter signups?” With context (ICP, channels, constraints, tech stack, lead magnet ideas), the model can produce a working plan in minutes.
The broader field is pushing the same direction: frameworks like MODP (Multi Objective Directional Prompting) formalize prompting as a multi-objective optimization (task success + model behavior) and report production use at Dell for “Next Best Action” support tooling. Research is catching up to what practitioners have learned the hard way. arXiv+1
The New Mindset — Think Like an Editor, Not a Searcher
By 2026, “prompt fluency” will be table stakes like spreadsheets. The job isn’t to memorize magic incantations; it’s to edit the task until the model can execute. That means clear intent, relevant context, and a format the next human can use without rework.
Building Contextual Prompts as Mini Briefs for Your LLM

Create quick templates you can adapt:
Persona + Goal (“You’re a CFO… reduce DSO by 10%…”)
Inputs (industry, constraints, data points)
Deliverable (policy draft, table, SOP, slide outline)
Guardrails (tone, exclusions, citations, length)
Education and governance circles are codifying this into curricula and responsible design practices. Expect prompts to carry not just utility requirements, but ethics/traceability (e.g., documenting assumptions, evaluation, and ownership). ACM Digital Library
Why Prompting Is a Skill Every Knowledge Worker Will Need by 2026
Marketing playbooks are already evolving for LLM-first discovery. HBR’s guidance: optimize content so LLMs can understand who you serve and for what — not just rank for a keyword. If your content (and your prompts) don’t express intent and context, you’ll be invisible in AI-mediated journeys. Harvard Business Review
Next Steps — Practice, Refine, and (Actually) Collaborate
Run controlled prompt tests: Write 3 versions of the same task (role/format/constraints different). Compare outputs and save the winner for reuse. arXiv+1
Adopt a “brief first” habit: Spend 60 seconds on context before you type. Your future self will thank you. Wharton Generative AI Labs
Instrument your prompts: Keep a lightweight log of prompt → outcome → edits needed. That’s your personal optimization dataset. arXiv
Layer responsibility: Include source/citation requirements, evaluation checks, and exclusions when it matters. (Regulated work? Treat the prompt like policy.) ACM Digital Library
Join our community: Interact, learn, and grow with other AI users. Share prompt templates, compare outputs, and pressure-test ideas together — because craft beats guesswork.


Comments